Creating a Smoother ML Workflow
Background
I recently encountered a bug where my wake word model struggled with audio samples captured through my headphones. This isn't surprising since the model had been trained exclusively with recordings captured through my laptop's microphone.
In order to fix this, I'd have to retrain the model with voice recordings from both my laptop and my headphones. Since this can be an error prone exercise, I decided it would be worthwhile investing in workflow improvements to make the process easier for the reasons I shared here:
Developing an accurate model often looks like this:
It will involve multiple iterations of tweaking data, training your model, and evaluating the results. To quickly converge onto an accurate model, it's important to invest time upfront to try and shorten each step of the loop. In my case, building additional tooling to more efficiently create a training set would have saved me a lot of time.
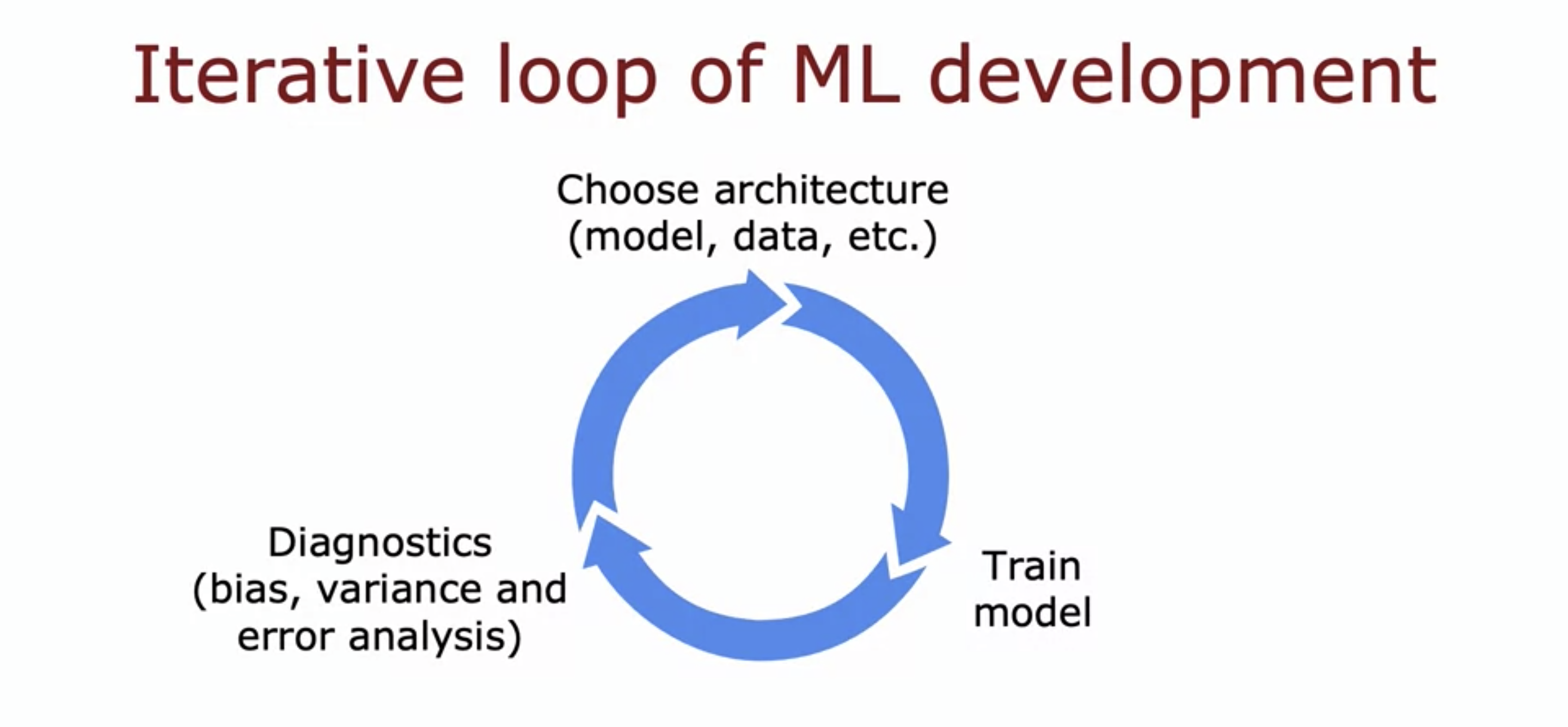
In this blog post, I'll share some of the specific tooling improvements that I made for retraining this model, and also share why they were helpful.
Workflow Improvements
Previous Workflow
To better understand the benefits of the improvements I made to the training workflow, it's helpful to understand the original workflow. It looked roughly like this:
- Data Collection: Run a script to manually record different data samples
- Data Duplication: Use a separate script to create multiple copies of each data sample
- Data Formatting: Run yet another script to convert the duplicated data into a list of JSON objects, with each entry containing the file path and it's respective label.
- Model Training: Run yet another script to train the model using the formatted data.
- Model Evaluation: Run one final script to evaluate the model against the dev set
Single Training Pipeline
One of the first improvements I made to this training process was combining steps 2-5 in the workflow into one single pipeline. The previous approach of running multiple scripts sequentially had several downsides:
- Cognitive Overhead: I had to mentally keep track of all the scripts needed to train the model end-to-end.
- Manual Interaction: I had to be present at my computer throughout the entire training process since I had to manually run the next script the moment the previous one was finished.
- Data Cleanup: I had to manually clean up all the intermediary data created in between each scripts after the training process was finished.
A single pipeline that did all the necessary data preprocessing, training and evaluation of the model fixed each of these painpoints. It also made it easier for me to test multiple versions of the model to see which one performed best.
Data Labeling Tool
I also created a tool to make it easier to label samples that are automatically collected when using my test app. Previously, collecting new samples to train the model required a separate step to intentionally record different samples. This had the following downsides:
- Separate Data Collection Step: New samples generated while testing the model in my test app couldn't be directly incorporated into the training process.
- Data Formatting: I needed a separate script to convert all the collected samples into the appropriate JSON format for the training pipeline.
In order to address these two pain points, I created a simple tool that would:
- Automatically collect samples I created while using my test app. These were placed into an "unlabeled" folder.
- Display these "unlabeled"samples in a UI where they could be manually labeled. It looked like this:
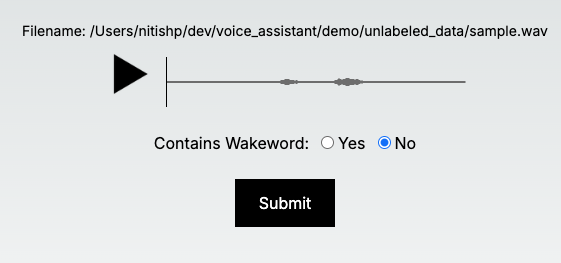
Once I hit "Submit", it would add the sample and it's correct label into a JSON file. This JSON file could be used as input directly into the training pipeline I mentioned in the previous section. It would also remove this sample from the "unlabeled" folder since it no longer needed to be labeled again.
Results
These two workflow improvements simplified both data collection and model training. This made the process of retraining the model with data collected through my headphones much simpler.
To evalute the impact of this retraining, I created a new dev set that consisted of samples collected from both my laptop microphone as well as through my headphones. Here's how the original version of the model performed against this dev set:
Laptop Microphone Headphone
----- --------------------------------- ---------------------------------
True 12 / 12, Percentage: 1.0 1 / 12, Percentage: 0.08333333333
False 11 / 12, Percentage: 0.9166666666 12 / 12, Percentage: 1.0
Overall accuracy: 36 / 48, Percentage: 0.75
Unsurprisingly, the original model struggled with samples collected through my headphones. After training the model with data collected through my headphones, here's the result on the same dev set:
Laptop Microphone Headphone
----- -------------------------------- ------------------------
True 4 / 12, Percentage: 0.3333333333 12 / 12, Percentage: 1.0
False 12 / 12, Percentage: 1.0 12 / 12, Percentage: 1.0
Overall accuracy: 40 / 48, Percentage: 0.8333333334
As you can see, the model performed much better with data collected through my headphones, but it now struggled with samples collected through my laptop's microphone. Based on the training logs, this is likely happening because the model is overfitting to noise in the training data.
Simplifying the model could help with this, and this is something I'll explore in a future post. The workflow improvements shared in this post should make it much easier to study this!