Improving Wake Word Model Performance
Background
A few months ago, I trained a model to predict if an audio clip contained the phrase "Hey Jarvis", which you can read about in more detail here. The model worked to some extent, but it often misclassified audio clips that had a segment of the wake word phrase. For example, the model would predict true if it was given an audio clip with the phrase "Hey".
I recently took a stab at trying to improve this model's accuracy in these types of cases. In this post, I'll share some key takeaways as well as the process I followed for this project.
Process
Is the Model Overfitting?
The first step I took was to determine if my model was overfitting to the training data. To debug this, I split up my data into a training set and a test set, and then evaluated the model's performance on both of them:
Train Set Accuracy: 0.971024
Test Set Accuracy: 0.999575
Since the accuracy for both sets of data was close, it looks like the model wasn't overfitting. This would need some further debugging.
Error Analysis on Real-World Examples
As a next step, I created a Python script and used pyaudio to record a bunch of audio samples of myself saying the following words multiple times ("Hey Jarvis", "Hey", "Jarvis", "Jared", "Hyundai", "Rodeo", "Hey Rodeo"). I labeled this set of samples as my new dev set.
I evaluated the model on each sample of the dev set and manually checked which ones it failed to predict correctly. I saw a lot of the words that were "close" to the wake word ("Hey", "Jarvis", "Jared") were being incorrectly classified.
To improve the model, I kept the same architecture but enhanced my training dataset with more examples of these "close" words, following the same training process as in my previous post.
I then checked the model's performance on the dev set:
Model V1 Accuracy: 0.632
Model V2 Accuracy: 0.978
Everything looked good; however, there was still one more issue.
The Last Problem
While evaluating my model using my Next.js app, I noticed the model had much lower accuracy.
I downloaded and saved the audio files sent to the server to debug why the model wasn't performing well. After manually listening to each of these samples, I noticed that they sounded different compared to my dev set even if I was saying the same phrase! It turned out the Python script that I had used to make the dev set recorded audio at a lower sample rate than MediaRecorder, which is what I had used in the Next.js app.
To resolve this, I created a new dev set using only samples collected from the Next.js app this time, and retrained the model similarly to the previous step.
Here's the results of the different model versions on the new dev set:
Model V1 Accuracy: 0.626
Model V2 Accuracy: 0.752
Model V3 Accuracy: 0.952
Key Takeaways
Optimize the ML development Loop
Developing an accurate model often looks like this:
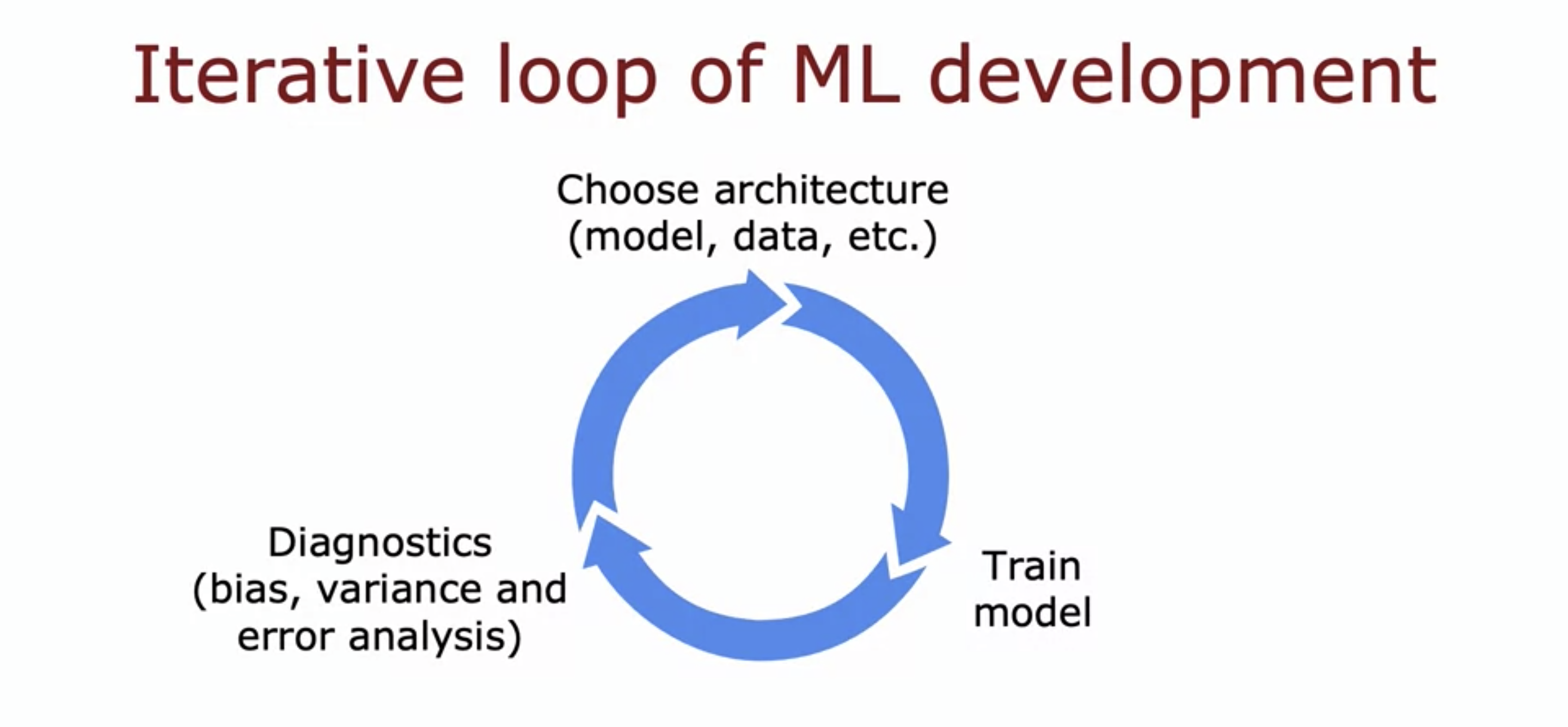
It will involve multiple iterations of tweaking data, training your model, and evaluating the results. To quickly converge onto an accurate model, it's important to invest time upfront to try and shorten each step of the loop. In my case, building additional tooling to more efficiently create a training set would have saved me a lot of time.
Ensure the Dev Set Represents the Real-World
While this may seem obvious, this was a major point in my project since I relied so heavily on synthetic data. I could have saved myself a few iterations of the ML Development loop, by initially creating a dev set with audio clips that accurately captured how my model would be evaluated in the real world.
Next steps
The process I used throughout this post would likely work well for other phrases that the wake word model incorrectly classifies. However, finding these incorrectly classified phrases and then collecting enough data samples to improve the model is quite time-consuming.
As a future enhancement, it might be worthwhile to explore transfer learning from a more powerful model performing a similar task. I'll explore this topic further in a future post!