Debugging Overfitting In a Model
Background
At the end of this post, I mentioned that my newly re-trained wake word model might have been overfitting to noise in the training data:
As you can see, the model performed much better with data collected through my headphones, but it now struggled with samples collected through my laptop's microphone. Based on the training logs, this is likely happening because the model is overfitting to noise in the training data.
Here's the data in the training logs I was referring to:
Training set accuracy: 0.99747
Test set accuracy: 0.99956
Dev set accuracy:: 0.83334
It's clear to see that the model performed well on data that it had already seen (training set), and on data that it had not seen that followed a similar distribution (test set). Yet it failed to generalize well to data that it would see in the "real world" (dev set) with the same accuracy. In general, this problem is called overfitting, and it can have quite a few causes such as:
- The underlying model being too complex
- The data that that the model is trained on not being representative of how it will be evaluated
- Not enough relevant features of the data being passed into the model.
For my particular case, I think #2 is the most likely culprit. In this post, I'll share some of my reasoning for this, as well as how I confirmed this suspicion.
Existing Setup
Before sharing the reasoning for my hypothesis, it's helpful to first understand all of the data sources I used, as well as how they were transformed before being passed into the model for training. I used three different sources of data:
- Test App Samples: This consisted of samples collected from my test app. These samples contained two sets of recordings of my voice: one saying the wakeword and one where I said short phrases that did not contain the wake word.
- Ambient Noise Data: This consisted of samples collected from my computer's built-in microphone recorded over the course of an hour. It consists of solely background environmental noise.
- Common Voice Data: This was a dataset of audio clips of people saying various phrases in different languages. Note that none of these contained the wake word. This was obtained from the Mozilla Common Voice dataset.
Since the overall number of samples used for the model was quite low, I duplicated samples that would be used for training the model, and then used SpecAugment to randomly remove frequencies in order to make the duplicated data slightly different.
This whole process is illustrated below:
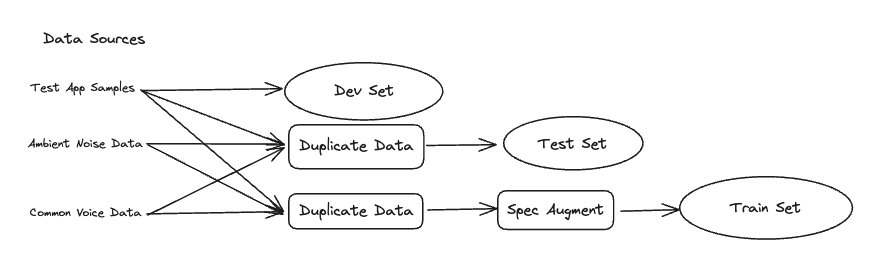
Ultimately, the way that the model would be evaluated would be through the test app, and that would just consist of samples of my voice. Given this fact, it's easy to see how I had the intuition that the data being used to train the model wasn't representative of how it would be evaluated. In particular, I was concerned that:
- The model was overfitting to noise in the Common Voice dataset, and thus sacrificing accuracy for the data collected through my test app.
- The SpecAugment methods used to modify duplicate samples of the data wasn't a realistic way of making tweaks to the data. In real life, I might say the wake word in a different pitch or with a slightly different speed. I was worried that the model might not be picking up on these more subtle differences in the sample.
Confirming my Hypothesis
In this section I'll share how I confirmed my hypothesis, and how I improved the model's accuracy.
Testing Data Sources
First I wanted to test out the data sources used to train the model in order to see which of them were actually helpful. In order to do this, I trained 3 different versions of the model and evaluated each of their performances on the dev set. Here's how the 3 models differed:
- Test App Samples Only: This version of the model used only data from the test app to train the model.
- Test App Samples and Ambient Noise Data: Similar to 1, but also added ambient noise data for training.
- Test App Samples, Ambient Noise, Common Voice Data: This was the existing setup used to train the model.
After training the model, here's how each of the models performed on the dev set:

As you can see, the model that had the highest dev set accuracy was the one that was trained only on samples from my test app and the ambient noise data. The model that was trained on only samples from my test app also did quite well. This helped confirm my theory that the model was overfitting to the data in the Common Voice dataset.
Testing Data Augmentation
I also wanted to test out the effect that different data augmentation techniques (duplication and SpecAugment) had on the model's performance. In order to evaluate this, I trained 5 different versions of the model. Note that all of these models were trained on the same data sources (test app samples and ambient noise samples) in order to keep things consistent. Here's how the 5 different models differed:
- Control: This was the version of the model from the previous experiment that used just test app samples and ambient noise data. It performed the same data duplication and SpecAugment as described in the "Existing Setup" section.
- No Duplication: This version of the model skipped duplicating samples, and also skipped the SpecAugment step.
- Only Duplication: This version of the model duplicated samples for training, but skipped the SpecAugment step.
- Duplication and Pitch Augmentation: This version of the model duplicated samples for training, and on a portion of the duplicate samples it randomly adjusted the pitch of the samples slightly up or down.
- Duplication and Speed Augmentation: Similar to the previous model but instead of adjusting the pitch, it randomly either sped up the audio sample a bit or slowed it down.
Here's how each of these models performed on the dev set:
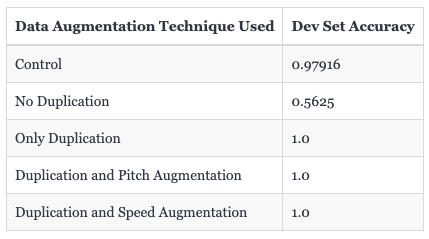
From these results, it's harder to definitively conclude which version of augmentation was most useful for improving the model's performance, but we can draw two conclusions:
- Duplicating the samples does provide more value than not having it at all. This is likely because without these extra samples the model doesn't have enough data to converge to a good set of parameters for its weights.
- SpecAugment might be slightly hurting the model's performance compared to not having it at all. This needs to be examined a bit more deeply before stating it as a definitive conclusion though since the accuracy gained on the dev set is quite small.
Conclusion
It looks like tweaking the data sources used to train the model had the biggest impact on improving it's accuracy, but from this whole process, I had two other important takeaways:
- Having a unified pipeline saves a lot of time: I evaluated 8 different versions of my model and without the pipeline that I created as part of improving my workflow, this whole process would have been a lot more time consuming.
- Adding more data to a model doesn't necessarily make it perform better: It's important to carefully evaluate the performance of each different data source or data augmentation technique on a dev set before deciding if it should be added to the training process.