Wake Word Detection Model
Background
I came across this awesome video by Michael where he described the process he used for creating a wake word detection model. I was really impressed by how little data he had to manually label (just 100 samples!), and figured this would be a great first machine learning project.
For my wake word, I decided to use "Hey Jarvis" and wrote this post to describe some of the theoretical knowledge I gained as well as some of the practical steps involved in training the model.
Demo
High Level Machine Learning Overview
To start, let's quickly define what a wake word detection algorithm is even supposed to do.
At a high level, the model's function is quite simple. It takes in a sequence of audio data and determines if that audio data contained the given phrase.
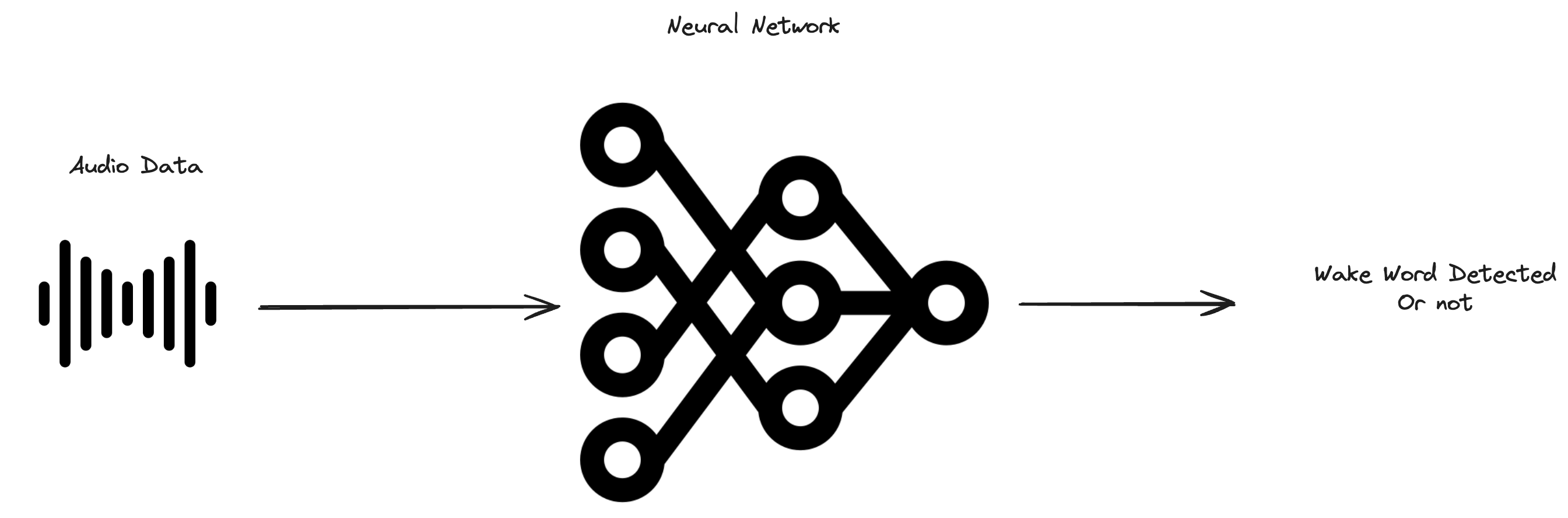
Notice that the output of this model can ever only be binary.
- 0 if the wake word was not present
- 1 if it was present.
This naturally means that our model is a binary classification model and for a loss function we can use the binary cross entropy loss function
Since our input data is audio data, we'd want to use Recurrent Neural Networks (RNNs) since these models are good at dealing with data that has variable time length. More specifically, for this problem, I chose to use a LSTM variant of a RNN. If you're not familiar with RNNs or LSTMs, I'd highly recommend this video by Statquest to understand them a little more at a high level.
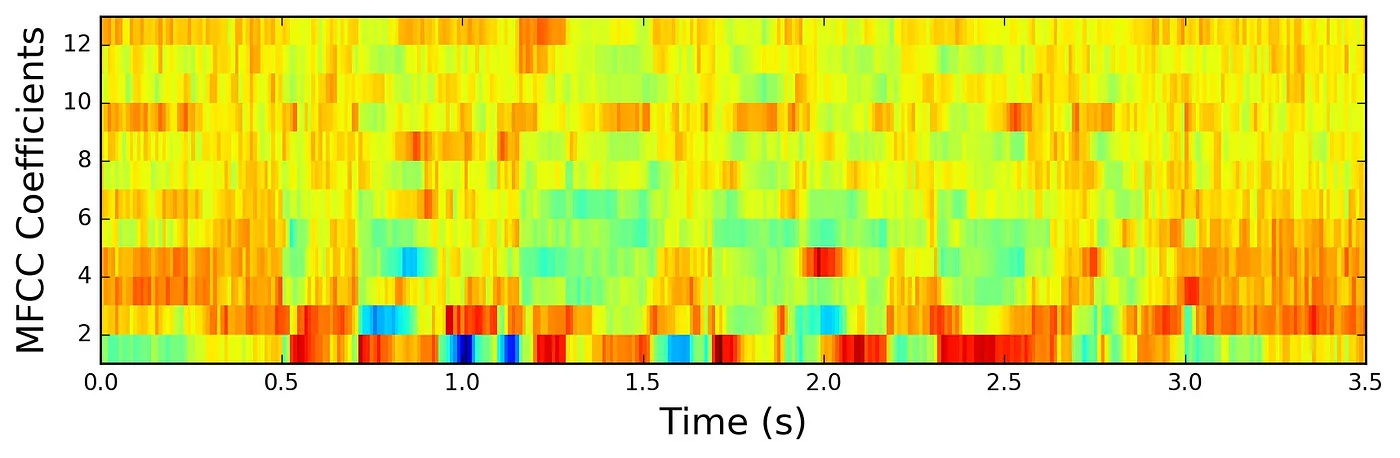
Finally, one last point to note about our model is that our input isn't the raw audio file that we get from the microphone. Instead, it's a Mel-frequency cepstrum (MFCC) of that audio file. At a high level, what this transformation does is strip out some of the noise from audio signals so we can feed important features into our model. It's used quite frequently in various machine learning problems involving audio data.
Collecting and Augmenting Data
Now that we've covered some of the setup for our model, we can start the process of collecting data to help train the model. In order to do this, we need two sets of labeled data.
The first set of data we need represents audio segments where the wake word was present. In order to take care of this, I recorded myself saying "Hey Jarvis" about 100 times. Each of these segments were about 1-2 seconds each.
The second set represents audio segments where the wake word was not present. To cover this, I needed samples where there was just background noise. To cover this case, I recorded random background noise on my computer for about 10 minutes, and split these into 1-2 second samples. This alone isn't enough to make a complete data set however, as if we trained the model with just this set of data, it would mark any segment with voice data as having detected the wake word. In order to account for this, we can use the Mozilla Common Voice dataset which has a bunch of audio clips of people saying different things that are not my wake word.
Finally, one last step to account for is with the data set we have created so far, we have a sample imbalance. We have far more data where the wake word was not present.
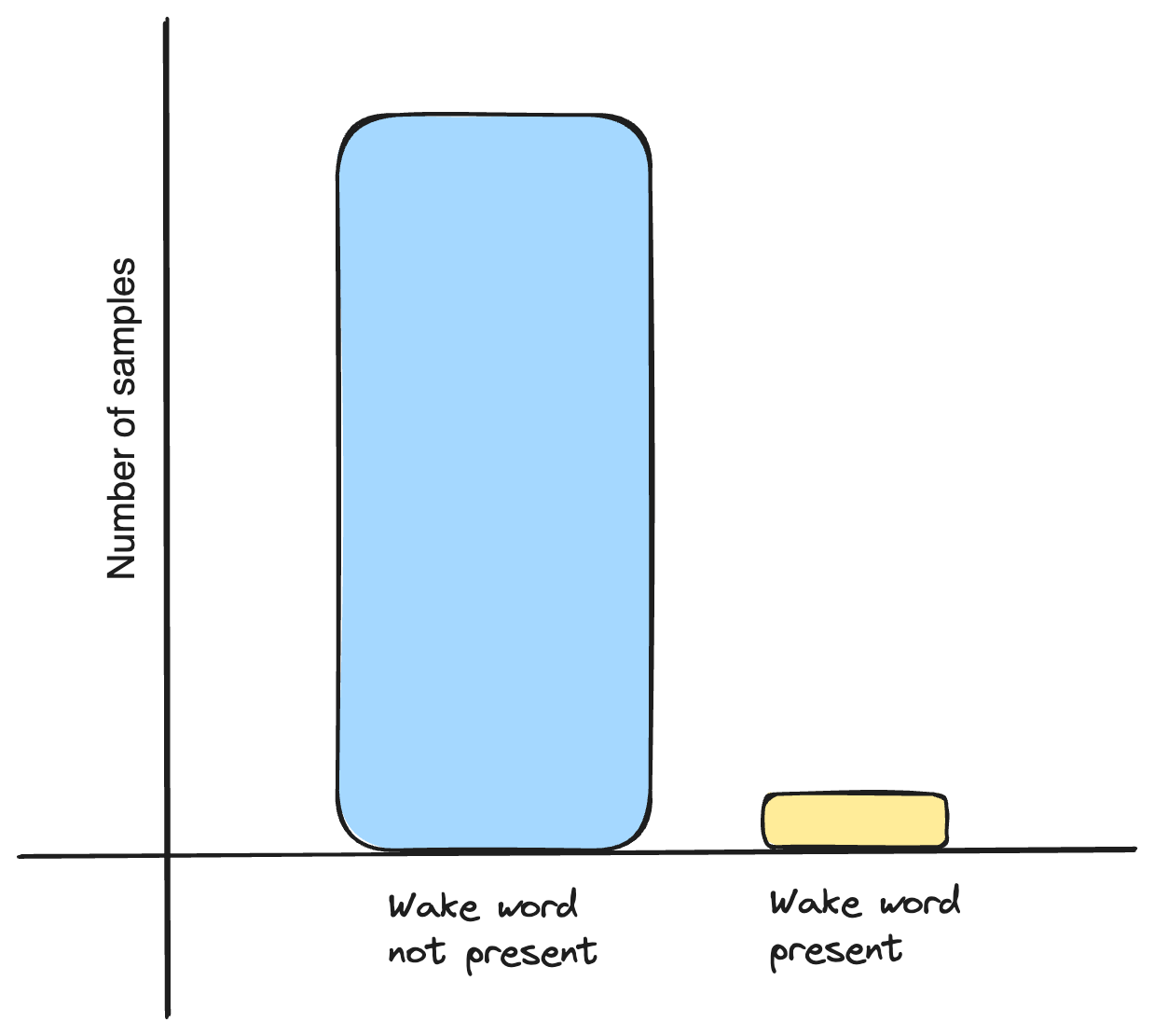
To account for this, we can duplicate the samples with the wake word present and use SpecAugment to remove random frequencies in order to make the copies a little bit different.
Closing Thoughts
As you can see from the demo video at the beginning, the model works quite well on my voice, but it would likely fail when trying to detect the wake word in someone else's voice. It also picks up phrases that are similar to "Hey Jarvis" and labels them as having detected the wakeword.
Both of these issues are because of the dataset we used to train the wakeword. The positive samples used to train the model were just samples of my voice, so different voices would be labeled as negative. The training set also doesn't cover samples that sounds similar to "Hey Jarvis", but aren't the wakeword.
In order to account for this, I'd need to expand the dataset used to cover these cases.