Leveraging Transfer Learning for Wakeword Detection
Background
In the past few blog posts, I've focused on building and fine-tuning an RNN-based wakeword detection model trained entirely from scratch. While that approach performs quite well, I've been curious using more modern methods of training and finetuning models — particularly transfer learning.
In this post, I'll share my process of finetune an existing model for my wakeword use case, and also share some lessons I learned along the way.
Transfer Learning
To quickly recap, transfer learning is the process of taking an existing model that has already been trained on a large, general dataset, and then fine-tuning its parameters for a smaller, task-specific dataset. This approach works with the assumption that some of the low-level features learned by the existing model can transfer effectively for the new task. So assuming that a well-matched existing model is selected for this task, the total time needed to fine-tune the model would be quite small - especially compared to training the existing model from scratch.
For this project, I used the AudioSpectogramTransformer, which you can read more about here. This model was trained and evaluated on AudioSet, ESC-50, and Speech Commands V2, all of which involve classifying short audio segments - similar to my wakeword detection problem.
I used the HuggingFace library for performing this task, and referenced this excellent guide for adapting AudioSpectogramTransformer (AST) for my use case.
Evaluation
Dev set
To fine-tune the AST model, I used only the Test App Samples described in more detail in this post, which consisted of just 385 samples of my voice. I evaluated the model against the same dev set I used for the RNN models, and the results are shown below:

As you can see, the model performs very well on the dev set, even without any data augmentations, which is already quite impressive compared to it's RNN counterpart.
Real World
Next, I wanted to gather some data to see how well the AST fine-tuned model performed in my Test App (described in more detail here)
In order to do this, I compared the AST model against the RNN that was trained with data duplication and augmentations.
Here are the results of these two models compared to one another:
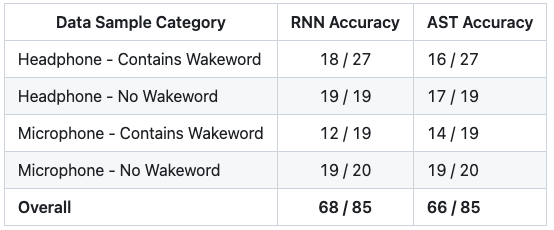
As you can see, the AST model performed on par with the RNN model which is quite impressive considering how few samples it needed to reach this level of accuracy.
However, I noticed that the AST model was much slower for inference. On average, it took ~0.5 seconds for the AST model to classify an audio sample, compared to ~0.01 seconds for the RNN model. This is likely due to the AST model being much larger and having significantly more parameteres compared to the RNN model.
Conclusion
Overall, I'm fairly impressed with the AST fine-tuned model, especially considering how few samples and how little feature engineering were required to achieve this level of performance. While there's clearly a performance hit when running inference for these larger models, I'm excited to explore this technique further in future posts.